
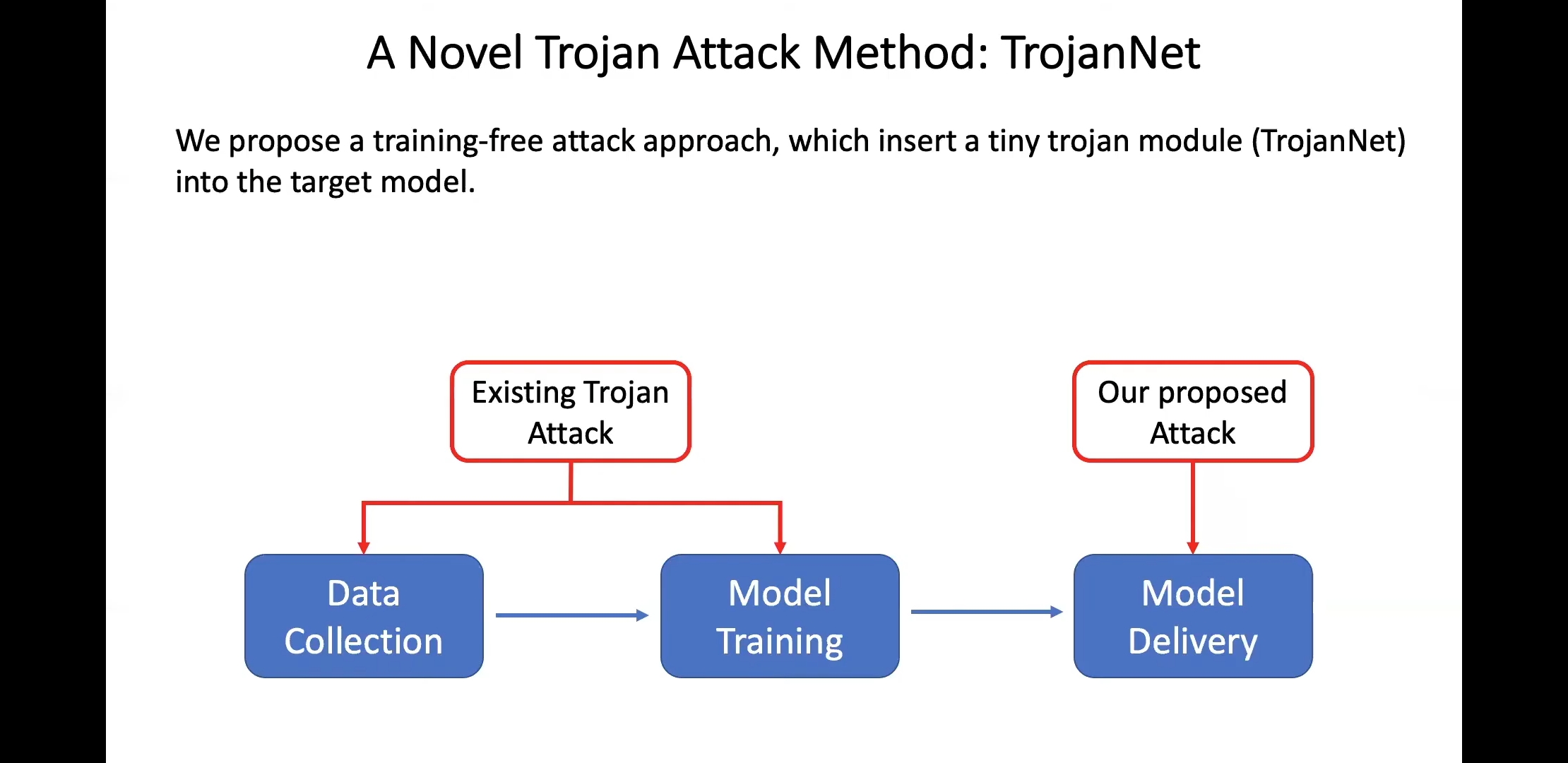
기존의 방법은 malicious data로 retraining 하여서 기존의 모델을 감염시켰다. 논문에서는 retraining 없이 직접 모델에 사전에 학습된 malicious layers(w/ parameters)를 삽입하여 특정 상황에 따를 감염동작을 야기하게끔 설계한다.
'Papers > Machine learning' 카테고리의 다른 글
| q-learning vs RLHF (0) | 2024.01.06 |
|---|---|
| Q-Star in openai (0) | 2024.01.06 |
| Meta-learning 종류 (0) | 2020.10.09 |
| Transfer learning vs. Finetuning (0) | 2020.09.15 |
| 차선(lane marking) 검출 알고리즘 (0) | 2020.09.12 |